
É frequente encontrarmos menções a modelos “Open Source” de Inteligência Artificial mas confesso que me causa um certo incômodo, me parece um uso mal ajustado e fora do contexto do termo.
O que a maioria das pessoas chama de “modelo open source” se refere na verdade aos parâmetros e pesos pré-calculados do modelo. Com uma implementação da arquitetura de inferência do modelo e seus pesos você pode realizar inferências no seu próprio equipamento. Comparando com o uso comum de software seria mais ou menos o equivalente a baixar e executar código binário fechado em uma plataforma de código aberto.
Para que um programa seja “open source sóftware” é necessário poder usá-lo para qualquer propósito, estudar o funcionamento de seus componentes, poder modificá-lo e redistribuí-lo sem restrições, tanto seu código quanto os resultados do seu uso. A disponibilidade do código fonte e do ferramental para produzir um binário executável são pré-requisitos para que um software seja “open source”.
Em um modelo de Machine Learning, a matéria prima que é transformada em pesos e parâmetros é sua base de treinamento. Como a base de treinamento é parte integral do “código fonte”, para que um modelo seja realmente “open source”, por equivalência, seus componentes e processos e ferramentas de treinamento também precisariam estar disponíveis.
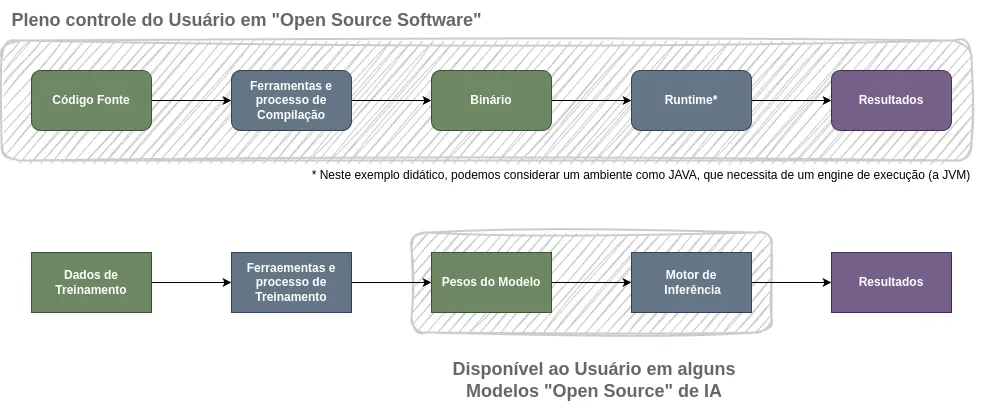
Um modelo que disponibiliza apenas pesos deveria ser chamado de “Open Weight Model” ou “Modelo de Pesos Abertos”, para evitar confusão com o conceito de “open source” de software. Um software aberto implica uma liberdade de uso e aplicação muito mais ampla do que os modelos ditos “open source” permitem e essa confusão pode facilmente levar a escolhas equivocadas ou mesmo problemas legais.
Aqui entram algumas definições e histórico úteis. O projeto Debian criou diretrizes para reconhecer software livre, que poderia fazer parte de sua distribuição, as Debian Free Software Guidelines (DFSG) foram a base para a criação da Open Source Initiative e sua Open Source Definition que tem sido referência confiável para a definição de “open source” há mais de 25 anos.
Recentemente a Open Source Initiative se posicionou oficialmente sobre o tema e lançou sua Open Source AI Definition 1.0, que se debruça e esclarece a equivalência do conceito de “open source” quando aplicado a modelos de I.A. é leitura obrigatória pra todos que se interessam em entender ou aplicar a tecnologia, especialmente aqueles que fazem uso de modelos locais, que estão cada vez mais acessíveis e deverão ter uma participação maior nas stacks de tecnologia da maioria das empresas nos próximos anos.
Se pode argumentar contra a relevância dessa definição precisa, dizer que é um preciosismo, já que é inviável treinar modelos de LLM do zero para a esmagadora maioria das organizações e impossível para indivíduos; que é possível “modificar” um modelo por fine tuning (“binary patching”?) sem precisar treiná-lo a partir do zero ou ter acesso a sua base de treinamento, portanto além de irrelevante também seria desnecessária.
Esses argumentos tem lugar valor, mas nem todo modelo em Machine Learning. é LARGE e a maior parte do valor gerado por IA no mundo corporativo até o momento não vem de LLM ou de I.A. Generativa, é sempre bom lembrar. Quanto aos Large Models, se tem alguma coisa que a gente vê continuamente em tecnologia é que as limitações de acesso e custo caem em menos tempo do que a maioria gasta se lamentando.
E, apesar de eu ter deixado por último, não é menos importante: a gente tem que levar em conta o desenvolvimento acadêmico. Para fazer ciência é preciso ser capaz de entender, reproduzir e criticar experimentos e resultados, divulgar e aprender a partir da pesquisa de outros cientistas. Incentivar modelos “Open Source” e ferramentas para reconhecê-los não é só importante para a academia, é Fundamental.
Comente de volta!